Excel is een veelzijdige applicatie die veel verder is gegroeid dan de eerdere versies, simpelweg als een spreadsheetoplossing. Werknemers zijn recordhouder, adresboek, prognosetool en nog veel meer. Veel mensen gebruiken Excel zelfs op een manier dat het nooit de bedoeling was.
Als u Excel veel thuis of op kantoor gebruikt, weet u dat de Excel-bestanden soms snel onwerkbaar worden vanwege het grote aantal records waarmee u werkt.
Gelukkig heeft Excel ingebouwde functies om dubbele records te vinden en te verwijderen. Helaas zijn er enkele kanttekeningen bij het gebruik van deze functies, dus wees voorzichtig of je kunt onbewust records wissen die je niet wilde verwijderen. Ook verwijderen beide methoden hieronder direct duplicaten zonder dat u kunt zien wat er is verwijderd.
Ik noem ook een manier om de rijen die het dubbele zijn eerst te markeren, zodat u kunt zien welke door de functies worden verwijderd voordat u ze uitvoert. U moet een aangepaste regel Voorwaardelijke opmaak gebruiken om een rij te markeren die volledig duplicaat is.
Functie duplicaten verwijderen
Stel dat u Excel gebruikt om adressen bij te houden en u vermoedt dat u dubbele records hebt. Bekijk het onderstaande Excel-werkblad:
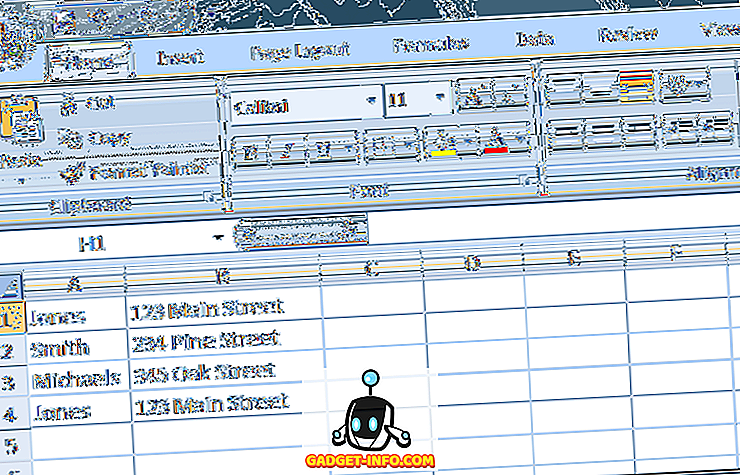
Merk op dat het "Jones" -record tweemaal verschijnt. Om dergelijke dubbele records te verwijderen, klikt u op het tabblad Gegevens op het lint en zoekt u de functie Duplicaten verwijderen onder het gedeelte Gegevenshulpmiddelen . Klik op Verwijder duplicaten en een nieuw venster wordt geopend.

Hier moet u een beslissing nemen op basis van of u koptekstlabels boven aan uw kolommen gebruikt. Als dat het geval is, selecteert u de optie met het label Mijn gegevens heeft kopteksten . Als u geen headinglabels gebruikt, gebruikt u de standaard kolomaanduidingen van Excel, zoals kolom A, kolom B, enzovoort.
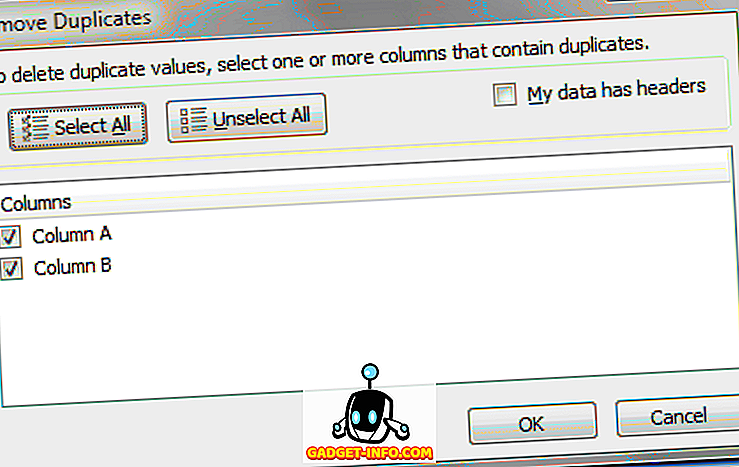
Voor dit voorbeeld kiezen we alleen kolom A en klik op de knop OK . Het optievenster wordt gesloten en Excel verwijdert het tweede "Jones" -record.
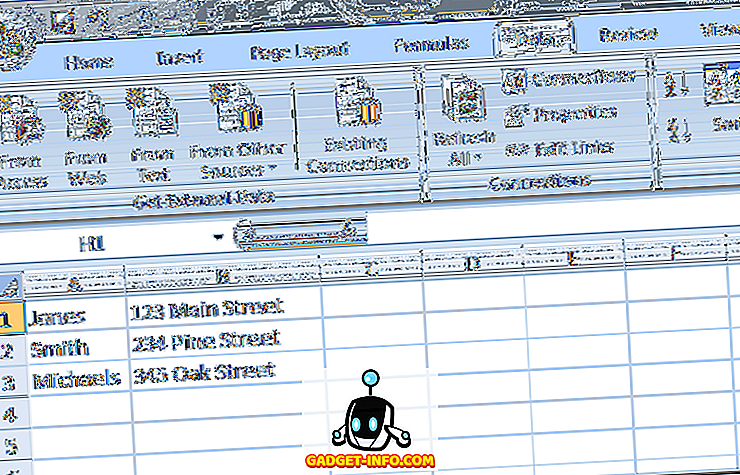
Natuurlijk was dit slechts een eenvoudig voorbeeld. Adresrecords die u in Excel blijft gebruiken, zijn waarschijnlijk veel gecompliceerder. Stel dat u bijvoorbeeld een adresbestand hebt dat er zo uitziet.
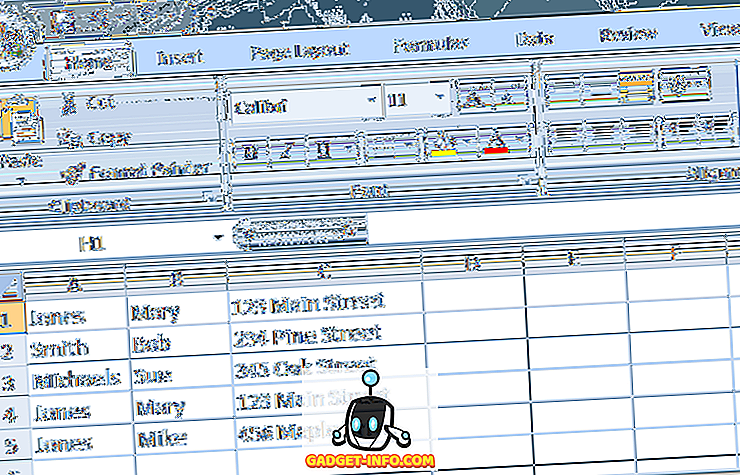
Merk op dat hoewel er drie "Jones" -records zijn, er slechts twee identiek zijn. Als we de bovenstaande procedures zouden gebruiken om dubbele records te verwijderen, zou er slechts één "Jones" -vermelding overblijven. In dit geval moeten we onze beslissingscriteria uitbreiden om zowel de voor- als achternaam in respectievelijk kolom A en B op te nemen.
Om dit te doen, klikt u opnieuw op het tabblad Gegevens op het lint en vervolgens op Duplicaten verwijderen . Deze keer, wanneer het optievenster verschijnt, kies je de kolommen A en B. Klik op de knop OK en merk op dat Excel deze keer slechts één van de records "Mary Jones" heeft verwijderd.
Dit komt omdat we Excel hebben verteld om duplicaten te verwijderen door records op basis van kolommen A en B te koppelen in plaats van alleen kolom A. Hoe meer kolommen u kiest, hoe meer criteria er moeten zijn voordat Excel een record als duplicaat beschouwt. Kies alle kolommen als u rijen wilt verwijderen die volledig duplicaat zijn.
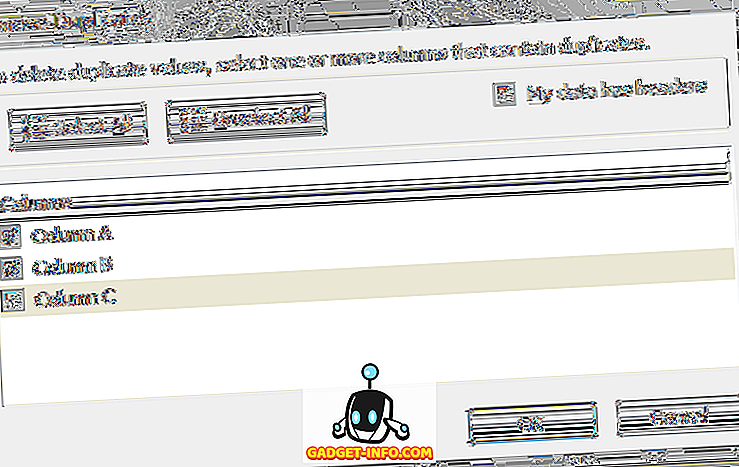
Excel geeft u een bericht dat u vertelt hoeveel duplicaten zijn verwijderd. Het laat echter niet zien welke rijen zijn verwijderd! Blader omlaag naar het laatste gedeelte om te zien hoe u de dubbele rijen eerst markeert voordat u deze functie uitvoert.

Geavanceerde filtermethode
De tweede manier om duplicaten te verwijderen, is door gebruik te maken van de geavanceerde filteroptie. Selecteer eerst alle gegevens in het blad. Klik vervolgens op het tabblad Gegevens in het lint op Geavanceerd in het gedeelte Sorteren en filteren .
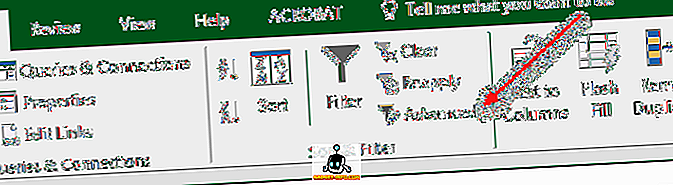
Vink in het dialoogvenster dat wordt weergegeven alleen het selectievakje Unieke records aan .
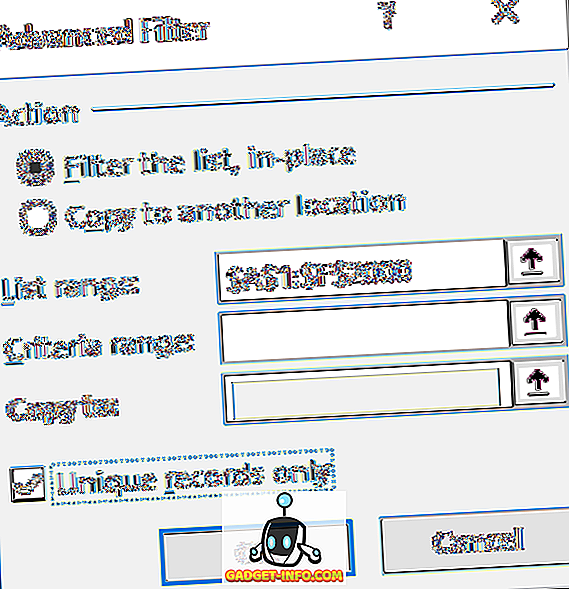
U kunt de lijst op de juiste plaats filteren of u kunt de niet-dubbele items naar een ander deel van dezelfde spreadsheet kopiëren. Om een vreemde reden kan je de gegevens niet kopiëren naar een ander blad. Als u het op een ander blad wilt, kiest u eerst een locatie op het huidige blad en knipt en plakt u die gegevens in een nieuw blad.
Met deze methode krijgt u niet eens een bericht waarin staat hoeveel rijen zijn verwijderd. De rijen zijn verwijderd en dat is het.
Markeer dubbele rijen in Excel
Als u wilt zien welke records duplicaat zijn voordat u ze verwijdert, moet u een beetje handmatig werk doen. Helaas heeft Excel geen manier om rijen te markeren die volledig duplicaat zijn. Het heeft een functie onder voorwaardelijke opmaak die dubbele cellen markeert, maar dit artikel gaat over dubbele rijen.
Het eerste wat u moet doen, is een formule toevoegen in een kolom rechts van uw dataset. De formule is eenvoudig: combineer alle kolommen voor die rij samen.
= A1 & B1 & C1 & D1 & E1
In mijn voorbeeld hieronder heb ik gegevens in de kolommen A tot en met F. De eerste kolom is echter een ID-nummer, dus ik sluit dat uit mijn onderstaande formule uit. Zorg ervoor dat u alle kolommen opneemt met gegevens waarop u duplicaten wilt controleren.

Ik heb die formule in kolom H geplaatst en vervolgens naar alle rijen gesleept. Deze formule combineert eenvoudig alle gegevens in elke kolom als één groot stuk tekst. Sla nu een aantal extra kolommen over en voer de volgende formule in:
= AANTAL.ALS ($ H $ 1: $ H $ 34, $ H1)> 1
Hier gebruiken we de AANTAL.ALS-functie en de eerste parameter is de verzameling gegevens waarnaar we willen kijken. Voor mij was dit kolom H (met de gegevensformule samengevoegd) van rij 1 tot en met 34. Het is ook een goed idee om de koprij te verwijderen voordat u dit doet.
Je moet ook zeker weten dat je het dollarteken ($) voor de letter en het cijfer gebruikt. Als u 1000 rijen gegevens heeft en uw gecombineerde rijformule staat bijvoorbeeld in kolom F, ziet uw formule er in plaats daarvan als volgt uit:
= AANTAL.ALS ($ F $ 1: $ F $ 1000, $ F1)> 1
De tweede parameter heeft alleen het dollarteken voor de kolomletter, zodat deze is vergrendeld, maar we willen het rijnummer niet vergrendelen. Nogmaals, u sleept dit naar beneden voor al uw rijen met gegevens. Het zou er zo uit moeten zien en de dubbele rijen zouden TRUE in zich moeten hebben.
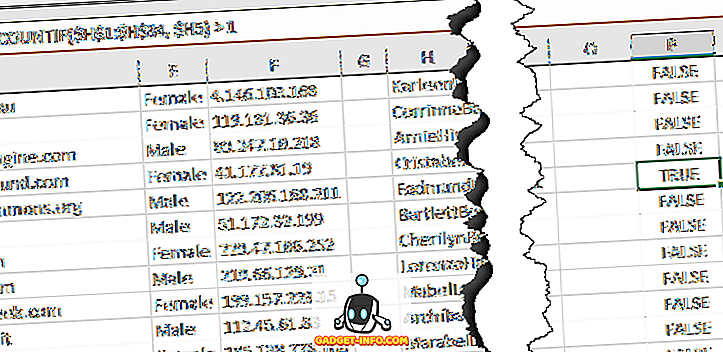
Laten we nu de rijen met WAAR markeren, omdat dit de dubbele rijen zijn. Selecteer eerst het volledige werkblad met gegevens door op het driehoekje bovenaan links in de rij van rijen en kolommen te klikken. Ga nu naar het tabblad Start, klik vervolgens op Voorwaardelijke opmaak en klik op Nieuwe regel .
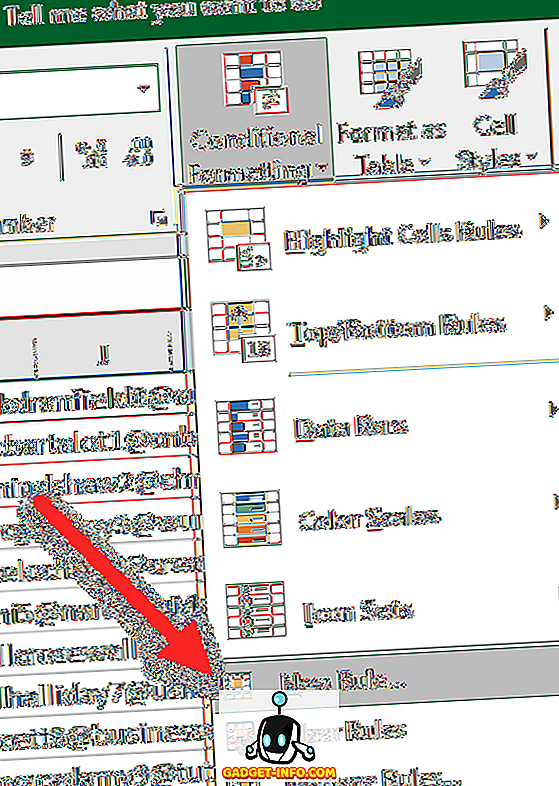
Klik in het dialoogvenster op Een formule gebruiken om te bepalen welke cellen moeten worden opgemaakt .
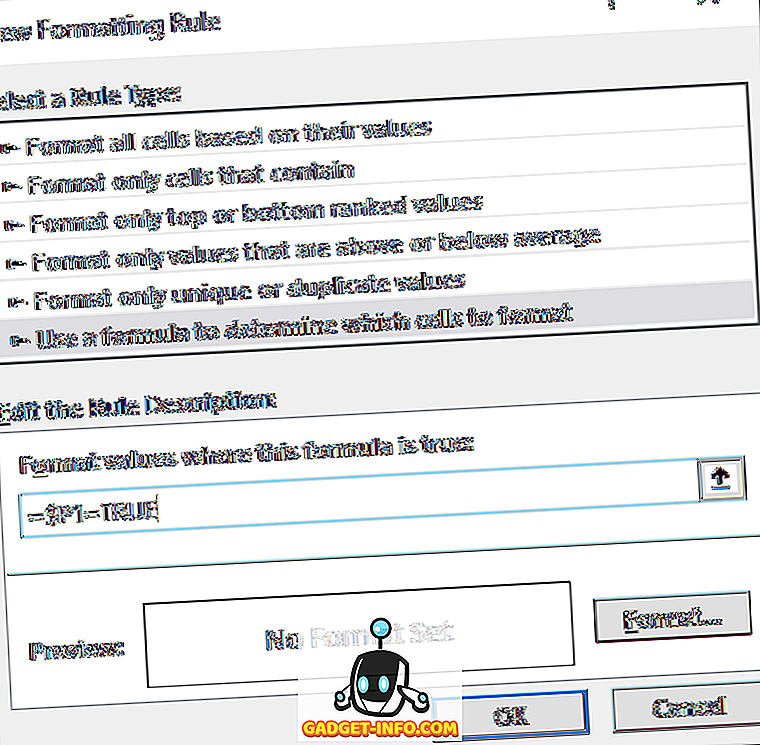
Typ in het vak onder Waarden noteren waar deze formule waar is:, voer de volgende formule in, waarbij P wordt vervangen door uw kolom met de waarden WAAR of ONWAAR. Zorg ervoor dat u het dollarteken voor de kolomletter plaatst.
= $ P1 = TRUE
Als je dat hebt gedaan, klik je op Formaat en klik je op het tabblad Opvulling. Kies een kleur en die wordt gebruikt om de hele dubbele rij te markeren. Klik op OK en je zou nu zien dat de dubbele rijen zijn gemarkeerd.
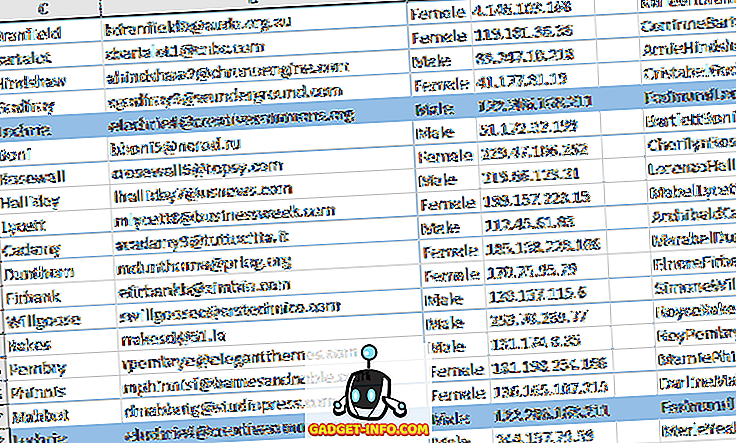
Als dit niet voor u werkt, begin opnieuw en doe het langzaam opnieuw. Het moet precies goed worden gedaan om dit alles te laten werken. Als je onderweg een enkel $ -symbool mist, zal het niet goed werken.
Voorbehoud bij het verwijderen van dubbele records
Er zijn natuurlijk een paar problemen met het automatisch laten verwijderen van dubbele records door Excel. Ten eerste moet je voorzichtig zijn met het kiezen van te weinig of te veel kolommen voor Excel om te gebruiken als criteria voor het identificeren van dubbele records.
Te weinig en mogelijk wist u onbedoeld records die u nodig hebt. Te veel of inclusief een kolom met identificatoren per ongeluk en geen duplicaten worden gevonden.
Ten tweede neemt Excel altijd aan dat het eerste unieke record dat het tegenkomt de stamrecord is. Van alle volgende records wordt aangenomen dat ze duplicaten zijn. Dit is een probleem als u bijvoorbeeld een adres van een van de personen in uw bestand niet hebt gewijzigd, maar een nieuw record hebt gemaakt.
Als de nieuwe (correcte) adresrecord wordt weergegeven na de oude (verouderde) record, gaat Excel ervan uit dat de eerste (verouderde) record de master is en verwijdert alle volgende records die worden gevonden. Dit is de reden waarom u voorzichtig moet zijn met hoe royaal of conservatief u Excel laat bepalen wat wel of geen duplicaat is.
Voor die gevallen moet u de methode voor het dupliceren van markeringen gebruiken waarover ik heb geschreven en de bijbehorende dubbele record handmatig verwijderen.
Ten slotte vraagt Excel niet om te verifiëren of u echt een record wilt verwijderen. Met behulp van de parameters die u kiest (kolommen), is het proces volledig geautomatiseerd. Dit kan gevaarlijk zijn wanneer u een groot aantal records hebt en u vertrouwt erop dat de beslissingen die u hebt genomen correct waren en dat Excel de dubbele records automatisch voor u kan verwijderen.
Bekijk ook ons vorige artikel over het verwijderen van lege regels in Excel. Genieten!