De bandbreedte die in de UMA in het geheugen wordt gebruikt, is beperkt omdat deze een enkele geheugencontroller gebruikt. Het belangrijkste motief van de komst van NUMA-machines is om de beschikbare bandbreedte in het geheugen te verbeteren door meerdere geheugencontrollers te gebruiken.
Vergelijkingstabel
| Basis voor vergelijking | UMA | NUMA |
|---|---|---|
| basis- | Gebruikt een enkele geheugencontroller | Meerdere geheugencontroller |
| Type gebruikte bussen | Enkel, meervoudig en dwarsbalk. | Boom en hiërarchisch |
| Geheugentoegangstijd | Gelijk | Veranderingen afhankelijk van de afstand van de microprocessor. |
| Geschikt voor | Applicaties voor algemene doeleinden en time-sharing | Real-time en tijdkritieke applicaties |
| Snelheid | langzamer | sneller |
| bandbreedte | Beperkt | Meer dan UMA. |
Definitie van UMA
UMA (Uniform Memory Access) -systeem is een gedeelde geheugenarchitectuur voor de multiprocessors. In dit model wordt een enkel geheugen gebruikt en toegankelijk gemaakt door alle processors die het multiprocessorsysteem presenteren met behulp van het interconnectienetwerk. Elke processor heeft een gelijke geheugentoegangstijd (latency) en toegangssnelheid. Het kan gebruikmaken van een enkele bus, meerdere bus of crossbar-schakelaar. Omdat het een gebalanceerde gedeelde geheugentoegang biedt, is het ook bekend als SMP (Symmetric Multiprocessor) -systemen.
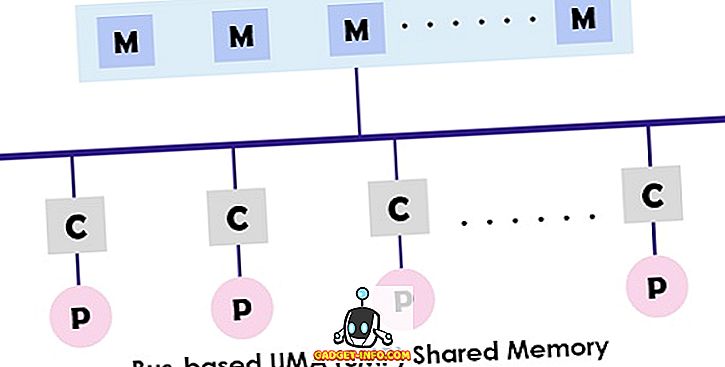
Het typische ontwerp van de SMP wordt hierboven getoond, waarbij elke processor eerst wordt verbonden met de cache en vervolgens wordt de cache gekoppeld aan de bus. Eindelijk is de bus verbonden met het geheugen. Deze UMA-architectuur vermindert de strijd voor de bus door de instructies rechtstreeks uit de individuele geïsoleerde cache te halen. Het biedt ook een gelijke kans op lezen en schrijven naar elke processor. De typische voorbeelden van het UMA-model zijn Sun Starfire-servers, Compaq alpha-server en HP v-serie.
Definitie van NUMA
NUMA (Non-uniform Memory Access) is ook een multiprocessormodel waarbij elke processor is verbonden met het toegewezen geheugen. Deze kleine delen van het geheugen vormen echter samen één adresruimte. Het belangrijkste punt om hier over na te denken is dat in tegenstelling tot UMA de toegangstijd van het geheugen afhankelijk is van de afstand waarop de processor wordt geplaatst, wat betekent dat de toegangstijd voor het geheugen varieert. Het biedt toegang tot elke geheugenlocatie door het fysieke adres te gebruiken.
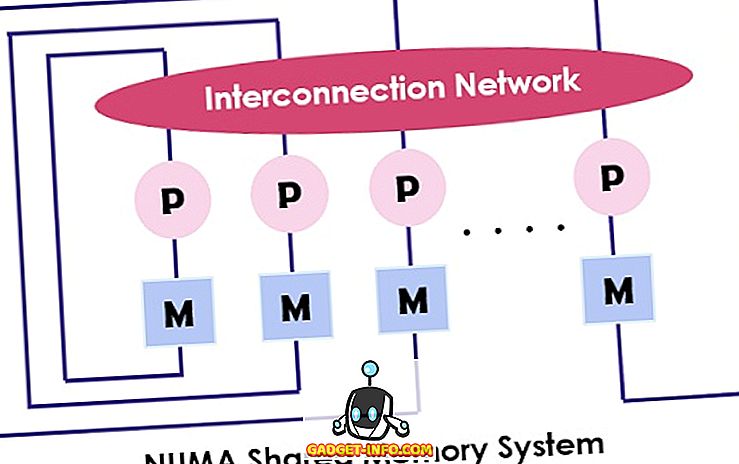
Zoals hierboven vermeld, is de NUMA-architectuur bedoeld om de beschikbare bandbreedte naar het geheugen te vergroten en waarvoor het meerdere geheugencontrollers gebruikt. Het combineert talrijke machine-kernen tot " knooppunten ", waarbij elke kern een geheugencontroller heeft. Om toegang te krijgen tot het lokale geheugen in een NUMA-machine haalt de kern het geheugen op dat door de geheugencontroller wordt beheerd door zijn knooppunt. Terwijl toegang wordt verkregen tot het geheugen op afstand dat door de andere geheugencontroller wordt afgehandeld, zendt de kern het geheugenverzoek via de interconnectielinks.
De NUMA-architectuur gebruikt de boom en hiërarchische busnetwerken om de geheugenblokken en de processors met elkaar te verbinden. BBN, TC-2000, SGI Origin 3000 en Cray zijn enkele voorbeelden van de NUMA-architectuur.
Belangrijkste verschillen tussen UMA en NUMA
- Het UMA (shared memory) -model maakt gebruik van een of twee geheugencontrollers. Daarentegen kan NUMA meerdere geheugencontrollers hebben om toegang te krijgen tot het geheugen.
- Enkele, meervoudige en dwarsbalkbussen worden gebruikt in UMA-architectuur. Omgekeerd gebruikt NUMA hiërarchische en boomtype bussen en netwerkverbindingen.
- In UMA is de geheugentoegangstijd voor elke processor hetzelfde, terwijl in NUMA de geheugentoegangstijd verandert naarmate de afstand van het geheugen van de processor verandert.
- Applicaties voor algemene doeleinden en time-sharing zijn geschikt voor de UMA-machines. De juiste toepassing voor NUMA daarentegen is realtime en tijdkritisch centraal.
- De op UMA gebaseerde parallelle systemen werken langzamer dan de NUMA-systemen.
- Als het gaat om bandbreedte UMA, beperkte bandbreedte. Integendeel, NUMA heeft meer bandbreedte dan UMA.
Conclusie
De UMA-architectuur biedt dezelfde algehele latentie voor de processors die toegang hebben tot het geheugen. Dit is niet erg handig wanneer het lokale geheugen wordt geopend omdat de latentie uniform zou zijn. Aan de andere kant had elke processor in NUMA zijn eigen geheugen dat de latentie elimineert wanneer het lokale geheugen wordt gebruikt. De latency verandert als de afstand tussen de processor en het geheugen verandert (dwz niet-uniform). NUMA heeft de prestaties echter verbeterd in vergelijking met UMA-architectuur.