Excel-spreadsheets bevatten vaak vervolgkeuzemenu's voor cellen om gegevensinvoer te vereenvoudigen en / of te standaardiseren. Deze vervolgkeuzemenu's worden gemaakt met behulp van de gegevensvalidatiefunctie om een lijst met toegestane items op te geven.
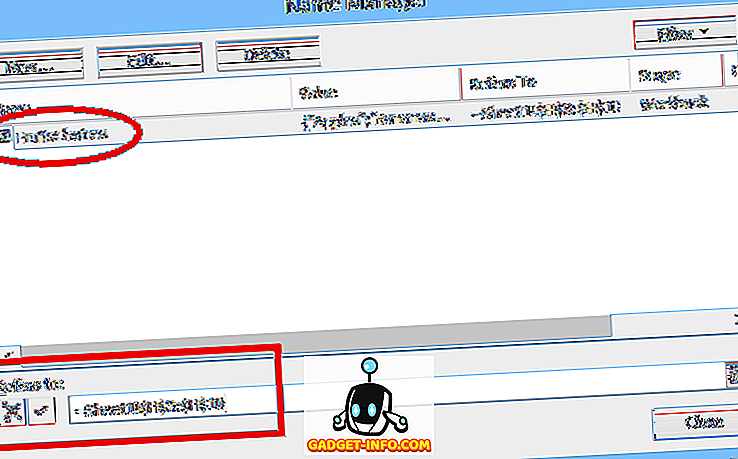
Om een eenvoudige vervolgkeuzelijst in te stellen, selecteert u de cel waar de gegevens worden ingevoerd, klikt u vervolgens op Gegevensvalidatie (op het tabblad Gegevens ), selecteert u Gegevensvalidatie, kiest u Lijst (onder Toestaan :) en voert u vervolgens de lijstitems in (gescheiden door komma's). ) in het veld Source : (zie Figuur 1).
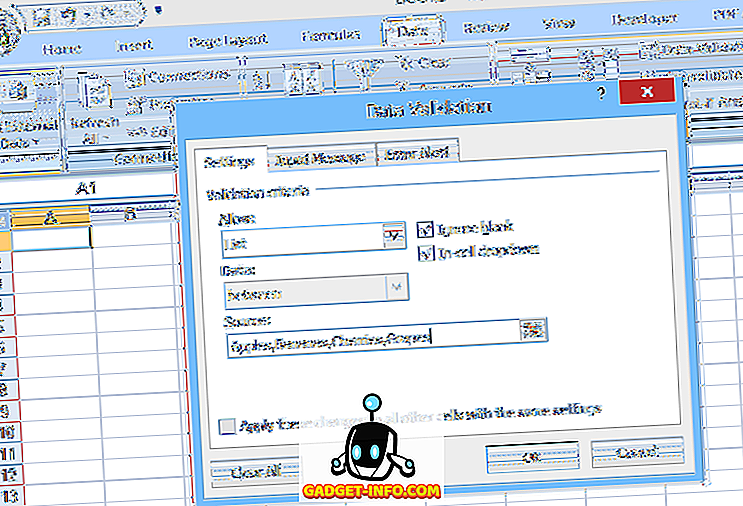
In dit type eenvoudige vervolgkeuzelijst wordt de lijst met toegestane items gespecificeerd binnen de gegevensvalidatie zelf; Daarom moet de gebruiker de gegevensvalidatie openen en bewerken om wijzigingen in de lijst aan te brengen. Dit kan echter moeilijk zijn voor onervaren gebruikers, of in gevallen waar de lijst met keuzes lang is.
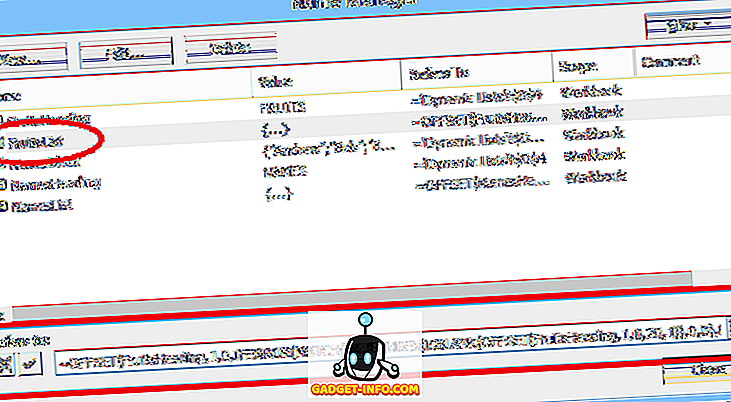
Een andere optie is om de lijst in een benoemd bereik in het werkblad te plaatsen en vervolgens die bereiknaam (voorafgegaan door een gelijkteken) op te geven in het veld Bron : van de gegevensvalidatie (zoals weergegeven in figuur 2).
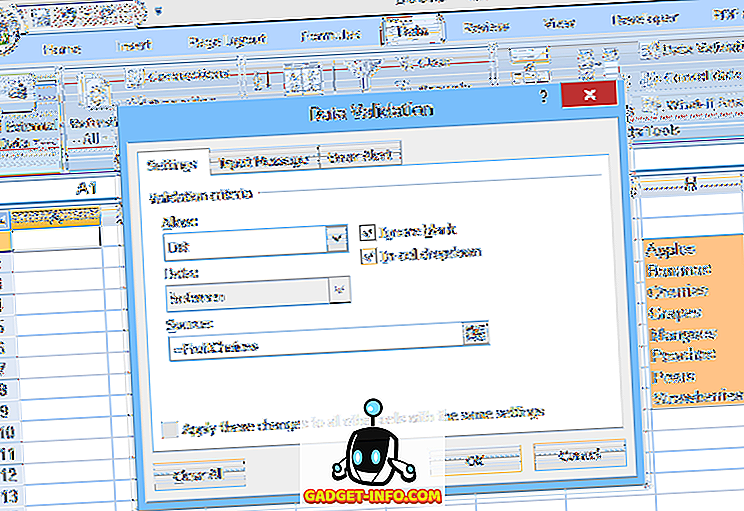
Deze tweede methode maakt het gemakkelijker om de keuzes in de lijst te bewerken, maar het toevoegen of verwijderen van items kan problematisch zijn. Omdat het genoemde bereik (FruitChoices, in ons voorbeeld) verwijst naar een vast cellenbereik ($ H $ 3: $ H $ 10 zoals weergegeven), worden er, als er meer keuzes worden toegevoegd aan de cellen H11 of lager, deze niet weergegeven in de vervolgkeuzelijst (aangezien deze cellen geen deel uitmaken van het FruitChoices-bereik).
Op dezelfde manier worden, als de items Peren en Aardbeien worden gewist, ze niet langer in de vervolgkeuzelijst weergegeven, maar in plaats daarvan bevat de vervolgkeuzelijst twee 'lege' keuzes, omdat de vervolgkeuzelijst nog steeds verwijst naar het hele FruitChoices-bereik, inclusief de lege cellen H9 en H10.
Om deze redenen, wanneer een normaal benoemd bereik wordt gebruikt als de lijstbron voor een vervolgkeuzelijst, moet het benoemde bereik zelf worden bewerkt om meer of minder cellen op te nemen als items worden toegevoegd of verwijderd uit de lijst.
Een oplossing voor dit probleem is om een dynamische bereiknaam te gebruiken als bron voor de vervolgkeuzemenu's. Een dynamische bereiknaam is een naam die automatisch wordt uitgevouwen (of wordt gecontracteerd) om exact overeen te komen met de grootte van een gegevensblok wanneer items worden toegevoegd of verwijderd. Hiervoor gebruikt u een formule in plaats van een vast bereik van celadressen om het benoemde bereik te definiëren.
Hoe een dynamisch bereik in te stellen in Excel
Een normale (statische) bereiknaam verwijst naar een opgegeven bereik van cellen ($ H $ 3: $ H $ 10 in ons voorbeeld, zie hieronder):
Maar een dynamisch bereik wordt gedefinieerd met behulp van een formule (zie hieronder, ontleend aan een afzonderlijke spreadsheet die dynamische bereiknamen gebruikt):
Voordat we beginnen, moet je ons Excel-voorbeeldbestand downloaden (sorteermacro's zijn uitgeschakeld).
Laten we deze formule in detail bekijken. De keuzes voor Fruit bevinden zich in een blok cellen direct onder een kop ( FRUITS ). Aan die kop is ook een naam toegewezen: FruitsHeading :
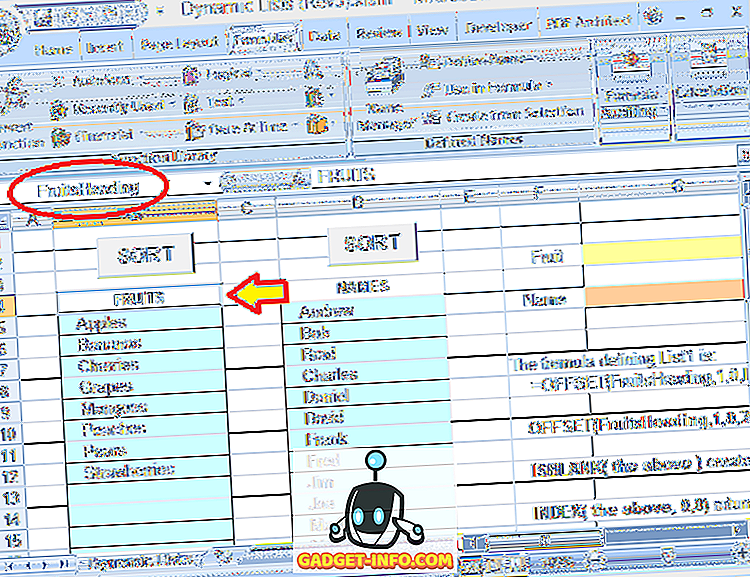
De volledige formule die wordt gebruikt om het dynamisch bereik voor de keuzes voor fruit te definiëren, is:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK (OFFSET (FruitsHeading, 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
FruitsHeading verwijst naar de kop die één rij boven de eerste vermelding in de lijst staat. Het getal 20 (twee keer gebruikt in de formule) is de maximale grootte (aantal rijen) voor de lijst (deze kan naar wens worden aangepast).
Let op: in dit voorbeeld zijn er slechts 8 vermeldingen in de lijst, maar er zijn ook lege cellen onder deze waar extra ingangen kunnen worden toegevoegd. Het getal 20 verwijst naar het hele blok waar invoer kan worden gemaakt, niet naar het werkelijke aantal vermeldingen.
Laten we nu de formule in stukjes splitsen (kleurcodering van elk stuk), om te begrijpen hoe het werkt:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( OFFSET (FruitsHeading, 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
Het "binnenste" stuk is OFFSET (FruitsHeading, 1, 0, 20, 1) . Dit verwijst naar het blok van 20 cellen (onder de cel FruitsHeading) waar keuzes kunnen worden ingevoerd. Deze OFFSET-functie zegt in feite: Begin bij de cel FruitsHeading, ga 1 rij en meer dan 0 kolommen omlaag en selecteer vervolgens een gebied dat 20 rijen lang en 1 kolom breed is. Dus dat geeft ons het 20-rijige blok waar de vruchten-keuzes worden ingevoerd.
Het volgende stuk van de formule is de ISLEEG- functie:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX ( ISBLANK (de bovenstaande), 0, 0), 0) -1, 20), 1)
Hier is de OFFSET-functie (hierboven uitgelegd) vervangen door "het bovenstaande" (om dingen gemakkelijker leesbaar te maken). Maar de functie ISBLANK werkt op het cellenbereik met 20 rijen dat de functie OFFSET definieert.
ISBLANK maakt vervolgens een set van 20 TRUE- en FALSE-waarden, waarmee wordt aangegeven of elk van de afzonderlijke cellen in het 20-rijbereik waarnaar wordt verwezen door de functie OFFSET leeg (leeg) is of niet. In dit voorbeeld zijn de eerste 8 waarden in de set ONWAAR, omdat de eerste 8 cellen niet leeg zijn en de laatste 12 waarden WAAR zijn.
Het volgende onderdeel van de formule is de INDEX-functie:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (de bovenstaande, 0, 0), 0) -1, 20), 1)
Nogmaals, "het bovenstaande" verwijst naar de hierboven beschreven functies ISBLANK en OFFSET. De functie INDEX retourneert een array die de 20 TRUE / FALSE-waarden bevat die zijn gemaakt met de functie ISBLANK.
INDEX wordt normaal gesproken gebruikt om een bepaalde waarde (of een reeks waarden) uit een gegevensblok te halen door een bepaalde rij en kolom (binnen dat blok) op te geven. Maar door de rij- en kolominvoer naar nul in te stellen (zoals hier wordt gedaan), retourneert INDEX een array met het volledige gegevensblok.
Het volgende stuk van de formule is de MATCH-functie:
= OFFSET (FruitsHeading, 1, 0, IFERROR ( MATCH (TRUE, bovenstaande, 0) -1, 20), 1)
De functie MATCH retourneert de positie van de eerste TRUE-waarde binnen de array die wordt geretourneerd door de INDEX-functie. Omdat de eerste 8 vermeldingen in de lijst niet leeg zijn, zijn de eerste 8 waarden in de matrix ONWAAR en de negende waarde is WAAR (aangezien de 9de rij in het bereik leeg is).
Dus de MATCH-functie retourneert de waarde 9 . In dit geval willen we echter echt weten hoeveel items in de lijst staan, dus trekt de formule 1 af van de MATCH-waarde (die de positie van de laatste invoer aangeeft). Dus uiteindelijk geeft MATCH (WAAR, het bovenstaande, 0) -1 de waarde van 8 .
Het volgende onderdeel van de formule is de ALS-FOUT-functie:
= OFFSET (FruitsHeading, 1, 0, IFERROR (de bovenstaande, 20), 1)
De functie IFERROR retourneert een alternatieve waarde als de eerste opgegeven waarde resulteert in een fout. Deze functie is opgenomen omdat, als het hele blok met cellen (alle 20 rijen) zijn gevuld met items, de MATCH-functie een fout retourneert.
Dit is omdat we de MATCH-functie vertellen om naar de eerste TRUE-waarde te zoeken (in de array van waarden van de functie ISBLANK), maar als GEEN van de cellen leeg is, wordt de hele array gevuld met FALSE-waarden. Als MATCH de doelwaarde (TRUE) niet kan vinden in de array die wordt gezocht, retourneert deze een fout.
Dus als de volledige lijst vol is (en daarom geeft MATCH een fout terug), retourneert de functie IFERROR in plaats daarvan de waarde 20 (wetende dat er 20 vermeldingen in de lijst moeten staan).
Als laatste, OFFSET (FruitsHeading, 1, 0, het bovenstaande, 1) retourneert het bereik waarnaar we op zoek zijn: begin bij de cel FruitsHeading, ga 1 rij en meer dan 0 kolommen omlaag en selecteer vervolgens een gebied dat echter vele rijen lang is er zijn vermeldingen in de lijst (en 1 kolom breed). Dus de hele formule samen zal het bereik teruggeven dat alleen de werkelijke vermeldingen bevat (tot aan de eerste lege cel).
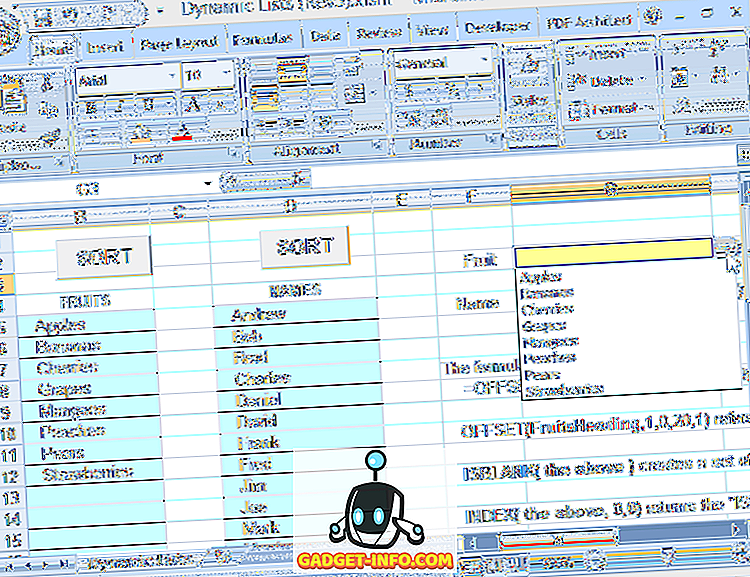
Als u deze formule gebruikt om het bereik te definiëren dat de bron voor de vervolgkeuzelijst is, kunt u de lijst vrij bewerken (vermeldingen toevoegen of verwijderen, zolang de resterende vermeldingen beginnen bij de bovenste cel en aaneengesloten zijn) en de vervolgkeuzelijst geeft altijd de huidige weer lijst (zie figuur 6).
Het voorbeeldbestand (dynamische lijsten) dat hier is gebruikt, is inbegrepen en kan worden gedownload van deze website. De macro's werken echter niet, omdat WordPress niet houdt van Excel-boeken met macro's erin.
Als een alternatief voor het opgeven van het aantal rijen in het lijstblok, kan aan het lijstblok een eigen bereiknaam worden toegewezen, die vervolgens in een gewijzigde formule kan worden gebruikt. In het voorbeeldbestand gebruikt een tweede lijst (namen) deze methode. Hier krijgt het volledige lijstblok (onder de kop "NAMES", 40 rijen in het voorbeeldbestand) de bereiknaam NameBlock . De alternatieve formule voor het definiëren van de namenlijst is dan:
= OFFSET (NamesHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock) ), 1)
waarbij NamesBlock OFFSET vervangt (FruitsHeading, 1, 0, 20, 1) en ROWS (NamesBlock) vervangt de 20 (aantal rijen) in de eerdere formule.
Dus, voor vervolgkeuzelijsten die gemakkelijk kunnen worden bewerkt (ook door andere gebruikers die mogelijk onervaren zijn), kunt u dynamische bereiknamen gebruiken! Merk op dat, hoewel dit artikel is gericht op vervolgkeuzelijsten, dynamische bereiknamen overal kunnen worden gebruikt om naar een bereik of lijst te verwijzen die in grootte kunnen variëren. Genieten!